Apoiada por US$ 8 milhões em financiamento inicial de Polychain e Borderless, juntamente com investidores de renome como Sreeram Kannan da EigenLabs, o ex-CTO da Coinbase Balaji Srinivasan e o cofundador da Polygon Sandeep Nailwal, a OpenLedger rapidamente ganhou força no setor de IA + blockchain.
Descubra a OpenLedger (OPEN), a primeira blockchain nativa de IA que torna dados, modelos e agentes transparentes e recompensáveis. Saiba como ela funciona, a utilidade e a tokenomics do token OPEN e os passos práticos para negociá-lo na BingX.
O que é a OpenLedger e como ela funciona?
A OpenLedger é uma blockchain construída especificamente para IA. Diferente das blockchains tradicionais projetadas para DeFi ou NFTs, a OpenLedger foca em tornar cada etapa do ciclo de vida da IA (contribuição de dados, treinamento de modelos, inferência e implantação) transparente e recompensável. Sua principal inovação é a Prova de Atribuição (Proof of Attribution, PoA), que rastreia como os dados influenciam os resultados do modelo e distribui as recompensas de acordo.
Da perspectiva do usuário, a OpenLedger é compatível com EVM e foi construída como um rollup OP Stack com a AltLayer como sua parceira RaaS. Isso significa que ela funciona com as ferramentas, carteiras e pontes familiares do Ethereum. O token OPEN serve como gas na L2 e impulsiona as recompensas baseadas em atribuição, tornando o ecossistema simples para desenvolvedores e acessível para colaboradores.
Na prática, a plataforma combina três ferramentas principais:
• Datanets: redes de dados compartilhadas e de propriedade da comunidade com proveniência verificável.
• ModelFactory: um painel sem código para ajuste fino e teste de modelos de IA.
• OpenLoRA: um sistema de serviço de baixo custo que pode hospedar milhares de modelos por GPU.
Este pipeline torna o desenvolvimento de IA mais rápido, barato e transparente, ao mesmo tempo que garante que os colaboradores sejam creditados sempre que seu trabalho for usado.
Tudo sobre o Airdrop de $OPEN
A OpenLedger também lançou um airdrop de tokens OPEN a partir de 8 de setembro de 2025, para recompensar seus primeiros apoiadores e participantes da testnet. Os usuários elegíveis incluíram aqueles que se pré-registraram, contribuíram com dados ou executaram nós durante as épocas da testnet, bem como membros ativos da comunidade de campanhas, snapshots da Cookie DAO e eventos do mundo real.
Os tokens foram distribuídos durante o Evento de Geração de Tokens (TGE) em setembro de 2025, com a opção de serem resgatados diretamente para as carteiras ou stake para recompensas maiores. Este airdrop marcou o primeiro passo na descentralização da propriedade do token e no alinhamento de incentivos em todo o ecossistema OpenLedger.
Leia mais: Airdrop da OpenLedger começa em 8 de setembro: Como resgatar tokens OPEN na Blockchain de IA
O que torna a OpenLedger diferente?
Diferente de blockchains de propósito geral ou projetos de IA que apenas se concentram em computação e armazenamento, a OpenLedger é focada em IA no nível do protocolo. Sua Prova de Atribuição (PoA) registra cada conjunto de dados, passo de treinamento e inferência do modelo on-chain, garantindo que os colaboradores sejam creditados e recompensados.
Com ferramentas como Datanets para conjuntos de dados de propriedade da comunidade, ModelFactory para ajuste fino sem código e OpenLoRA para implantação econômica, a OpenLedger transforma dados, modelos e agentes em ativos transparentes e monetizáveis, tornando a IA não apenas on-chain, mas também explicável, recompensável e pronta para produção.
O que é a Prova de Atribuição (PoA) da OpenLedger?
A PoA é o núcleo do protocolo. Ela mapeia quais dados influenciaram uma saída específica e, em seguida, direciona as recompensas de acordo. O whitepaper da PoA de junho de 2025 descreve duas abordagens:
1. Aproximações de função de influência para modelos menores.
2. Atribuição de token baseada em array de sufixos para LLMs que verifica tokens de saída em relação a corpora de treinamento compactados para detectar partes memorizadas.
Essa pontuação de influência se torna a base para os pagamentos no nível da inferência.
O recurso de PoA da OpenLedger torna a IA mais transparente, justa e confiável. Com a explicabilidade, você pode rastrear as respostas de um modelo até os dados que as moldaram; com a justiça, os colaboradores são recompensados sempre que sua entrada impulsiona resultados, não apenas quando eles a carregam; e com a conformidade, o sistema fornece registros de proveniência claros que ajudam com licenciamento, auditoria e atendimento a padrões regulatórios.
Visão Geral da Arquitetura do OpenLedger
Para entender como o OpenLedger funciona na prática, é útil olhar para seus blocos de construção principais. A plataforma combina ferramentas para compartilhamento de dados, treinamento de modelos e serviço com custo-benefício em um ecossistema unificado, tornando o desenvolvimento de IA mais transparente e acessível para todos.
1. Datanets
Datanets no OpenLedger | Fonte: OpenLedger
Pense em uma Datanet como um “clube de dados” público e on-chain para um tópico específico, por exemplo, contratos legais, trechos médicos, exploits de DeFi. Qualquer pessoa pode contribuir. Cada contribuição é codificada, atribuída e pode ser consultada posteriormente. Durante o treinamento e a inferência, o PoA pode medir a influência de cada contribuição e alocar recompensas.
O que torna as Datanets úteis
• Proveniência transparente para auditorias e licenciamento
• Incentivos para dados de qualidade (não apenas volume)
• Uma fonte limpa de conjuntos de dados de domínio específico para modelos especializados
2. ModelFactory
ModelFactory no OpenLedger
O ModelFactory é uma interface de ajuste fino apenas com GUI (não é necessário CLI). Escolha um modelo base, por exemplo, LLaMA/Mistral/DeepSeek, solicite conjuntos de dados com permissão de Datanets, configure LoRA/QLoRA e monitore o treinamento a partir de um painel de controle. Ele também oferece uma interface de chat/avaliação e atribuição RAG para ver por que uma resposta cita certas fontes.
3. OpenLoRA
O OpenLoRA se concentra em inferência com custo-benefício: ele carrega os adaptadores LoRA just-in-time, os mescla em tempo real e suporta streaming + quantização. Na prática, isso permite hospedar milhares de variantes ajustadas atrás de um modelo base compartilhado com baixa latência, em vez de iniciar um servidor separado por modelo.
Por que isso é importante: se você é um aplicativo com muitos modelos de nicho por cliente, país ou linha de produto, o OpenLoRA mantém os custos de GPU previsíveis enquanto mantém a velocidade. Esse padrão de "muitos adaptadores por GPU" é consistente com as tendências mais amplas de pesquisa de serviço LoRA.
Como Experimentar o OpenLedger como Iniciante
Você não precisa de habilidades técnicas profundas para explorar o OpenLedger. Aqui estão quatro maneiras simples de começar:
1. Explore na Testnet: Registre-se na testnet, configure sua carteira e experimente os recursos sem risco. Usuários técnicos podem executar um nó (via Docker ou similar) para apoiar a rede e ganhar pontos.
2. Contribua para uma Datanet: Escolha uma Datanet na sua área de especialização, como finanças, saúde ou segurança. Faça o upload de dados limpos e estruturados com metadados apropriados, como fonte e licença. Contribuições de qualidade podem posteriormente render recompensas de atribuição quando os modelos usarem seus dados.
3. Ajuste Fino um Modelo no ModelFactory: Use o painel sem código para selecionar um modelo base como LLaMA ou Mistral, defina os parâmetros e faça o ajuste fino com LoRA ou QLoRA. Teste as saídas instantaneamente com o módulo de chat e ative a atribuição RAG para que as respostas tenham fontes citadas e sejam confiáveis.
4. Sirva seu Modelo com o OpenLoRA: Implante seus modelos ajustados de forma eficiente, fazendo o upload de adaptadores LoRA. O carregamento dinâmico de adaptadores e o streaming de tokens mantêm a latência baixa, ao mesmo tempo que permitem que você escale para vários clientes ou domínios sem servidores adicionais.
Utilidade e Tokenomics do Token OPEN
O token OPEN é a espinha dorsal do ecossistema OpenLedger, projetado para conectar contribuidores, desenvolvedores e usuários sob um único sistema econômico. Ele potencializa funções essenciais que mantêm a rede em funcionamento e garantem que os participantes sejam recompensados de forma justa:
• Gas & Taxas: OPEN é o token de gas nativo para a L2 do OpenLedger. Cada transação, execução de contrato inteligente, implantação de modelo ou contribuição de dados requer OPEN, tornando-o o combustível do ecossistema.
• Governança: Os detentores de tokens ganham direitos de voto por meio de uma estrutura modular de Governador, permitindo-lhes decidir sobre atualizações de protocolo, programas de incentivo e políticas de atribuição que moldam a evolução do ecossistema.
• Recompensas de Atribuição: Graças ao Proof of Attribution (PoA), provedores de dados, construtores de modelos e agentes de IA ganham OPEN automaticamente sempre que seu trabalho contribui para o treinamento ou inferência do modelo, garantindo reconhecimento contínuo além do upload inicial.
• Pagamentos & Liquidações: OPEN também funciona como meio de troca em aplicativos de IA, mercados descentralizados e transações entre agentes, permitindo a liquidação perfeita para serviços construídos na plataforma.
Distribuição do Token OPEN
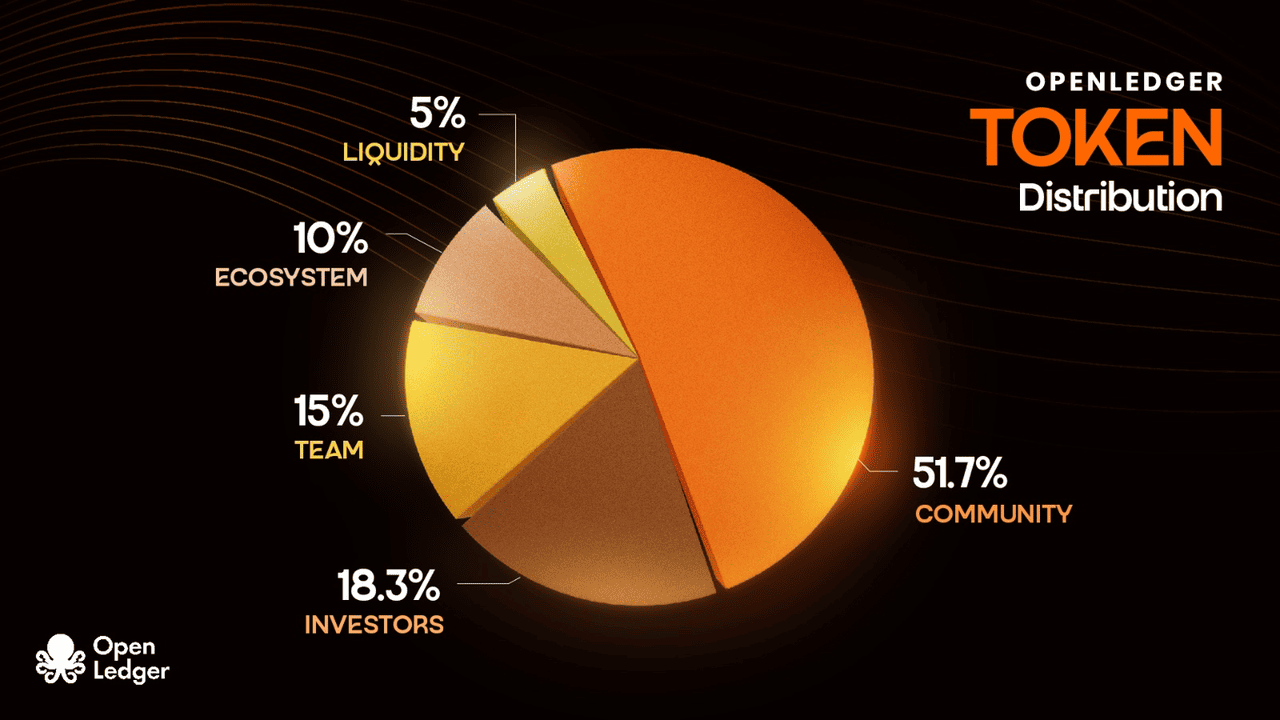
Alocação de token OPEN | Fonte: documentos do OpenLedger
O token OPEN (ticker: OPEN) segue o padrão ERC-20 com uma oferta total limitada a 1.000.000.000 de tokens, com uma oferta circulante inicial de 21,55%.
• Alocação para a Comunidade & Ecossistema: 61,7%, a maior parcela para colaboradores, desenvolvedores e crescimento do ecossistema
• Investidores: 18,3%
• Equipe: 15%
• Parcerias de Ecossistema: 10%
• Liquidez: 5%
Como negociar OPEN na BingX
Par de trading OPEN/USDT no mercado spot, com tecnologia de insights de IA da BingX
O par OPEN/USDT está disponível na BingX, dando aos traders acesso direto ao token nativo do ecossistema.
1. Crie e verifique sua conta BingX: Registre-se e conclua o KYC para ter acesso total.
2. Deposite USDT: Adicione fundos via cartão, transferência bancária ou transferindo cripto de outra carteira. Mova para sua conta Spot.
3. Procure por OPEN/USDT: No mercado Spot, digite “OPEN/USDT”.
4. Escolha o tipo de ordem:
• Ordem de Mercado → compre instantaneamente pelo preço atual.
• Ordem Limite → defina seu preço e espere o mercado alcançá-lo.
5. Confirme a negociação: Insira a quantia e clique em Comprar ou Vender.
6. Use as ferramentas de IA da BingX: Resuma notícias de mercado, defina um plano DCA (média de custo em dólar) ou monitore a volatilidade antes de tomar atitudes.
Dica: Fique de olho nas campanhas de listagem da BingX, as campanhas de depósito ou negociação antecipada podem incluir prêmios ou recompensas de bônus.
Conclusão
A OpenLedger visa trazer justiça, transparência e responsabilidade para a IA, tornando dados, modelos e agentes rastreáveis e monetizáveis on-chain. Com a Prova de Atribuição, os colaboradores podem finalmente ser reconhecidos e recompensados sempre que seu trabalho moldar as saídas da IA. Para os usuários, negociar OPEN/USDT na BingX oferece exposição direta ao projeto, enquanto ferramentas como Datanets, ModelFactory e OpenLoRA o tornam prático para desenvolvedores e provedores de dados.
Dito isso, a OpenLedger ainda é um ecossistema emergente. Como em todos os projetos de cripto, os riscos permanecem, desde vulnerabilidades de contratos inteligentes e volatilidade de tokens até incerteza regulatória. Se você decidir participar, comece com pouco, siga os canais oficiais e comprometa-se apenas com o que você pode perder.