Được hỗ trợ 8 triệu USD tài trợ ban đầu từ Polychain và Borderless, cùng với các nhà đầu tư cá nhân đáng chú ý như Sreeram Kannan của EigenLabs, cựu CTO Coinbase Balaji Srinivasan và đồng sáng lập Polygon Sandeep Nailwal, OpenLedger đã nhanh chóng tạo được động lực trong lĩnh vực AI + blockchain.
Khám phá OpenLedger (OPEN), blockchain AI-native đầu tiên giúp dữ liệu, mô hình và tác nhân trở nên minh bạch và có thể nhận thưởng. Tìm hiểu cách nó hoạt động, tiện ích và tokenomics của token OPEN, cùng các bước thực tế để giao dịch nó trên BingX.
OpenLedger là gì và nó hoạt động như thế nào?
OpenLedger là một blockchain được xây dựng dành riêng cho AI. Không giống như các blockchain truyền thống được thiết kế cho DeFi hoặc NFT, OpenLedger tập trung vào việc làm cho mọi bước trong vòng đời AI (đóng góp dữ liệu, đào tạo mô hình, suy luận và triển khai) trở nên minh bạch và có thể nhận thưởng. Đổi mới cốt lõi của nó là Bằng chứng Ghi công (Proof of Attribution - PoA), theo dõi cách dữ liệu ảnh hưởng đến kết quả đầu ra của mô hình và phân phối phần thưởng tương ứng.
Từ góc độ người dùng, OpenLedger tương thích với EVM và được xây dựng dưới dạng một OP Stack rollup với AltLayer làm đối tác RaaS. Điều này có nghĩa là nó hoạt động với các công cụ, ví và cầu nối Ethereum quen thuộc. Token OPEN đóng vai trò là gas trên L2 và cung cấp năng lượng cho các phần thưởng dựa trên ghi công, làm cho hệ sinh thái trở nên liền mạch cho các nhà phát triển và dễ tiếp cận với những người đóng góp.
Về mặt thực tế, nền tảng này kết hợp ba công cụ chính:
• Datanets: mạng lưới dữ liệu do cộng đồng sở hữu, có thể kiểm chứng nguồn gốc.
• ModelFactory: một bảng điều khiển không cần code để tinh chỉnh và thử nghiệm các mô hình AI.
• OpenLoRA: một hệ thống phục vụ hiệu quả về chi phí, có thể lưu trữ hàng nghìn mô hình trên mỗi GPU.
Hệ thống này giúp phát triển AI nhanh hơn, rẻ hơn và minh bạch hơn, đồng thời đảm bảo những người đóng góp được ghi nhận khi công việc của họ được sử dụng.
Tất cả về Airdrop $OPEN
OpenLedger cũng đã triển khai airdrop token OPEN bắt đầu từ ngày 8 tháng 9 năm 2025, để thưởng cho những người ủng hộ sớm nhất và những người tham gia testnet. Những người dùng đủ điều kiện bao gồm những người đã đăng ký trước, đóng góp dữ liệu hoặc chạy node trong các kỷ nguyên testnet, cũng như các thành viên cộng đồng tích cực từ các chiến dịch, ảnh chụp nhanh của Cookie DAO và các sự kiện thực tế.
Token đã được phân phối trong Sự kiện Tạo Token (TGE) vào tháng 9 năm 2025, với tùy chọn claim trực tiếp vào ví hoặc staking để nhận thưởng thêm. Airdrop này đánh dấu bước đi đầu tiên trong việc phi tập trung hóa quyền sở hữu token và điều chỉnh các ưu đãi trong toàn bộ hệ sinh thái OpenLedger.
Điều gì làm OpenLedger khác biệt?
Không giống như các blockchain đa mục đích hoặc các dự án AI chỉ tập trung vào tính toán và lưu trữ, OpenLedger đặt AI lên hàng đầu ở cấp độ giao thức. Bằng chứng Ghi công (PoA) của nó ghi lại mọi bộ dữ liệu, bước đào tạo và suy luận mô hình trên chuỗi, đảm bảo những người đóng góp được ghi nhận và thưởng.
Với các công cụ như Datanets cho các bộ dữ liệu do cộng đồng sở hữu, ModelFactory cho việc tinh chỉnh không cần code và OpenLoRA để triển khai hiệu quả về chi phí, OpenLedger biến dữ liệu, mô hình và tác nhân thành các tài sản minh bạch, có thể kiếm tiền, làm cho AI không chỉ on-chain mà còn dễ giải thích, có thể nhận thưởng và sẵn sàng cho sản xuất.
Bằng chứng Ghi công (PoA) của OpenLedger là gì?
PoA là cốt lõi của giao thức. Nó ánh xạ dữ liệu nào đã ảnh hưởng đến một đầu ra cụ thể, sau đó định tuyến phần thưởng tương ứng. Sách trắng PoA tháng 6 năm 2025 mô tả hai phương pháp:
1. Các xấp xỉ hàm ảnh hưởng cho các mô hình nhỏ hơn.
2. Ghi công token dựa trên mảng hậu tố cho các LLM, kiểm tra các token đầu ra với các tập dữ liệu đào tạo được nén để phát hiện các đoạn được ghi nhớ.
Điểm ảnh hưởng đó trở thành cơ sở cho các khoản thanh toán cấp suy luận.
Tính năng PoA của OpenLedger làm cho AI trở nên minh bạch, công bằng và đáng tin cậy hơn. Với tính dễ giải thích, bạn có thể truy vết câu trả lời của mô hình đến dữ liệu đã định hình chúng; với tính công bằng, những người đóng góp được thưởng bất cứ khi nào đầu vào của họ thúc đẩy kết quả, không chỉ khi họ tải lên; và với tính tuân thủ, hệ thống cung cấp các hồ sơ nguồn gốc rõ ràng giúp ích cho việc cấp phép, kiểm toán và đáp ứng các tiêu chuẩn quy định.
Tổng quan về kiến trúc của OpenLedger
Để hiểu cách OpenLedger hoạt động trong thực tế, việc xem xét các khối xây dựng cốt lõi của nó sẽ rất hữu ích. Nền tảng này kết hợp các công cụ để chia sẻ dữ liệu, huấn luyện mô hình và phục vụ với chi phí hiệu quả vào một hệ sinh thái hợp nhất, giúp việc phát triển AI trở nên minh bạch và dễ tiếp cận hơn cho mọi người.
1. Datanets (Mạng dữ liệu)
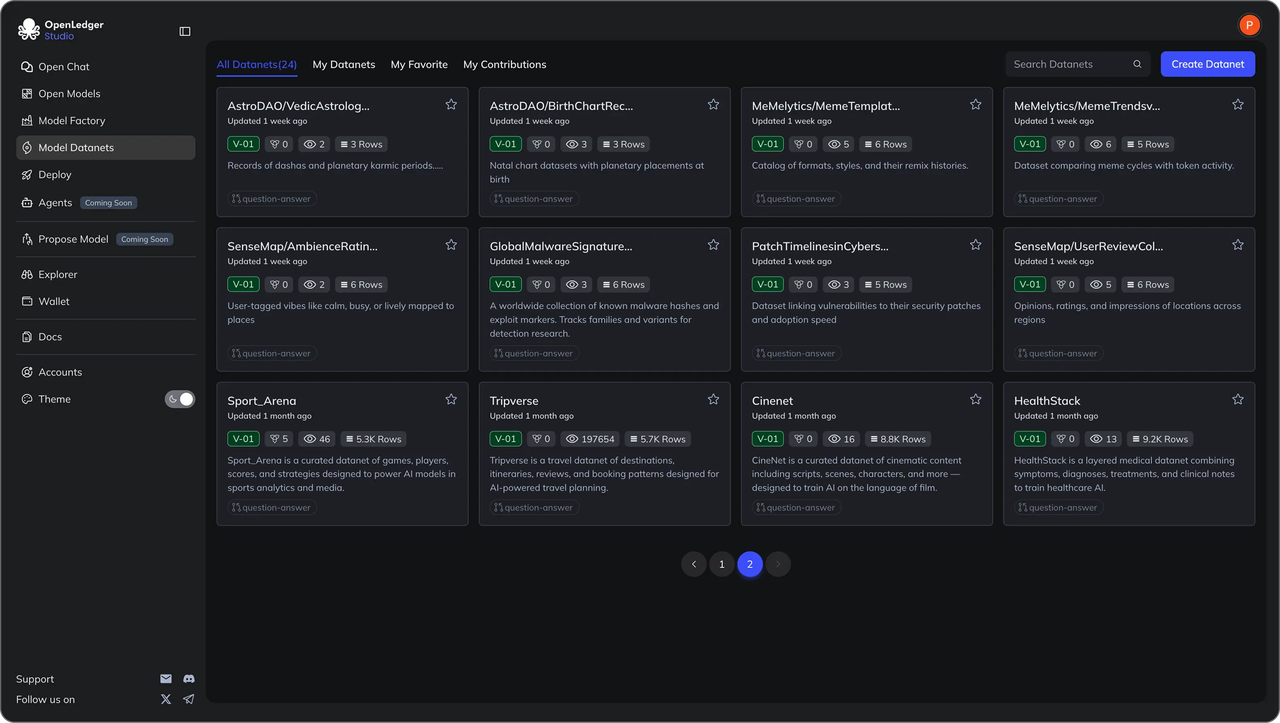
Datanets trên OpenLedger | Nguồn: OpenLedger
Hãy hình dung Datanet như một "câu lạc bộ dữ liệu" công khai, trên chuỗi cho một chủ đề cụ thể, ví dụ: hợp đồng pháp lý, đoạn trích y tế, lỗ hổng DeFi. Bất kỳ ai cũng có thể đóng góp. Mỗi đóng góp đều được băm, gán thuộc tính và có thể truy vấn sau này. Trong quá trình huấn luyện và suy luận, PoA (Bằng chứng Thuộc tính) có thể đo lường ảnh hưởng của mỗi đóng góp và phân bổ phần thưởng.
Điều gì làm cho Datanets hữu ích
• Nguồn gốc minh bạch để kiểm toán và cấp phép
• Khuyến khích dữ liệu chất lượng (không chỉ số lượng)
• Nguồn dữ liệu sạch, chuyên biệt cho các mô hình chuyên môn hóa
2. ModelFactory (Nhà máy Mô hình)
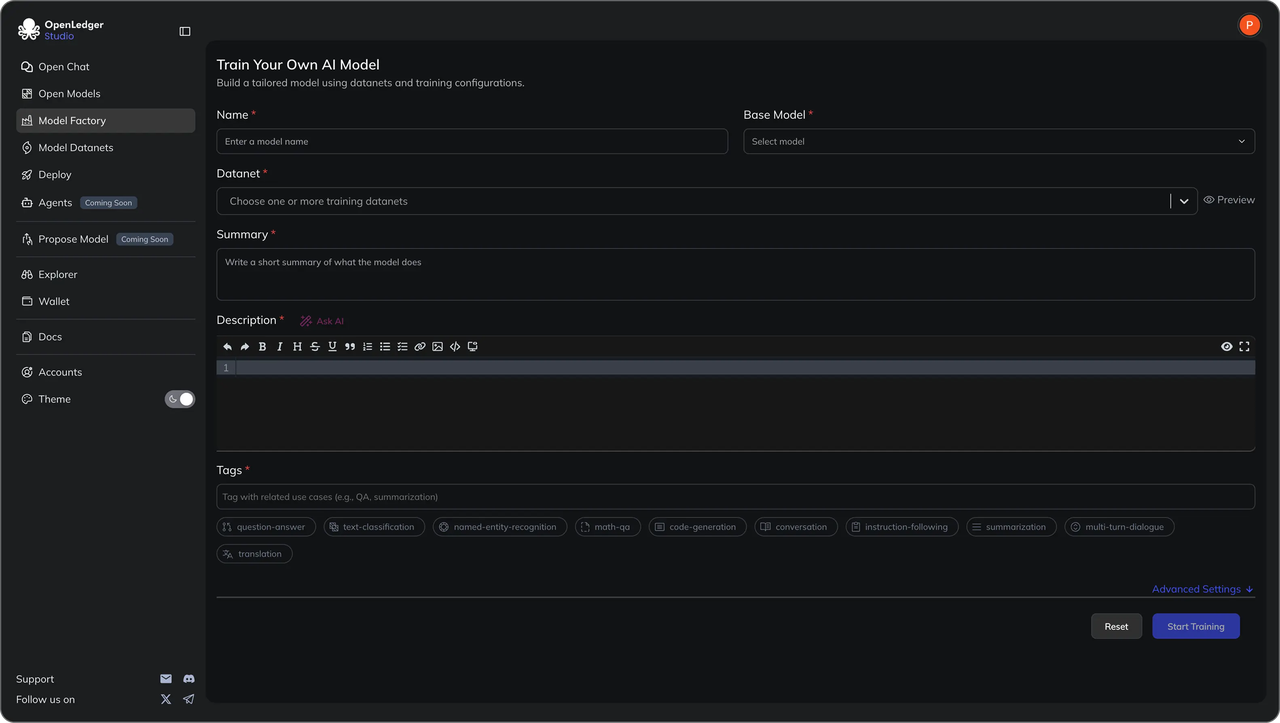
ModelFactory trên OpenLedger
ModelFactory là giao diện tinh chỉnh chỉ có GUI (không cần CLI). Người dùng có thể chọn một mô hình cơ sở, ví dụ: LLaMA/Mistral/DeepSeek, yêu cầu các bộ dữ liệu được cấp phép từ Datanets, cấu hình LoRA/QLoRA và theo dõi quá trình huấn luyện từ bảng điều khiển. Nó cũng đi kèm với một giao diện trò chuyện/đánh giá và tính năng thuộc tính RAG để xem tại sao một câu trả lời lại trích dẫn một số nguồn nhất định.
3. OpenLoRA
OpenLoRA tập trung vào suy luận với chi phí hiệu quả: nó tải các bộ điều hợp LoRA đúng lúc, hợp nhất chúng ngay lập tức và hỗ trợ truyền phát & lượng tử hóa. Trong thực tế, điều này cho phép bạn lưu trữ hàng ngàn biến thể được tinh chỉnh phía sau một mô hình cơ sở dùng chung với độ trễ thấp, thay vì phải khởi động một máy chủ riêng cho mỗi mô hình.
Tại sao điều này quan trọng: nếu bạn là một ứng dụng có nhiều mô hình chuyên biệt theo khách hàng, quốc gia, dòng sản phẩm, OpenLoRA giúp chi phí GPU có thể dự đoán được trong khi vẫn duy trì tốc độ. Mô hình "nhiều bộ điều hợp trên một GPU" này nhất quán với các xu hướng nghiên cứu về phục vụ LoRA rộng hơn.
Cách thử OpenLedger cho người mới bắt đầu
Bạn không cần kỹ năng kỹ thuật chuyên sâu để khám phá OpenLedger. Dưới đây là bốn cách đơn giản để bắt đầu:
1. Khám phá trên Testnet: Đăng ký trên testnet, thiết lập ví của bạn và thử các tính năng mà không gặp rủi ro. Người dùng có kỹ năng kỹ thuật có thể chạy một nút (thông qua Docker hoặc tương tự) để hỗ trợ mạng và kiếm điểm.
2. Đóng góp vào một Datanet: Chọn một Datanet trong lĩnh vực chuyên môn của bạn, chẳng hạn như tài chính, y tế hoặc an ninh. Tải lên dữ liệu sạch, có cấu trúc với siêu dữ liệu phù hợp như nguồn và giấy phép. Các đóng góp chất lượng sau này có thể kiếm được phần thưởng thuộc tính khi các mô hình sử dụng dữ liệu của bạn.
3. Tinh chỉnh một mô hình trong ModelFactory: Sử dụng bảng điều khiển không cần mã để chọn một mô hình cơ sở như LLaMA hoặc Mistral, đặt các thông số và tinh chỉnh với LoRA hoặc QLoRA. Kiểm tra đầu ra ngay lập tức với mô-đun trò chuyện và bật thuộc tính RAG để làm cho các phản hồi được trích dẫn nguồn và đáng tin cậy.
4. Phục vụ mô hình của bạn với OpenLoRA: Triển khai các mô hình đã được tinh chỉnh của bạn một cách hiệu quả bằng cách tải lên các bộ điều hợp LoRA. Tải bộ điều hợp động và truyền phát token giữ độ trễ thấp, đồng thời cho phép bạn mở rộng quy mô trên nhiều khách hàng hoặc miền mà không cần thêm máy chủ.
Tiện ích và Tokenomics của OPEN Token
OPEN token là xương sống của hệ sinh thái OpenLedger, được thiết kế để kết nối những người đóng góp, nhà phát triển và người dùng dưới một hệ thống kinh tế. Nó cung cấp năng lượng cho các chức năng thiết yếu giúp mạng lưới hoạt động và đảm bảo người tham gia được thưởng công bằng:
• Gas & Phí: OPEN là token gas gốc cho L2 của OpenLedger. Mọi giao dịch, thực thi hợp đồng thông minh, triển khai mô hình hoặc đóng góp dữ liệu đều yêu cầu OPEN, biến nó thành nhiên liệu của hệ sinh thái.
• Quản trị: Người nắm giữ token có được quyền bỏ phiếu thông qua một khuôn khổ Quản trị mô-đun, cho phép họ quyết định về các nâng cấp giao thức, chương trình khuyến khích và chính sách thuộc tính định hình cách hệ sinh thái phát triển.
• Phần thưởng Thuộc tính: Nhờ Bằng chứng Thuộc tính (PoA), các nhà cung cấp dữ liệu, nhà xây dựng mô hình và các tác nhân AI tự động kiếm được OPEN bất cứ khi nào công việc của họ đóng góp vào việc huấn luyện hoặc suy luận mô hình, đảm bảo sự công nhận liên tục ngoài lần tải lên ban đầu.
• Thanh toán & Quyết toán: OPEN cũng hoạt động như phương tiện trao đổi trên các ứng dụng AI, thị trường phi tập trung và giao dịch giữa các tác nhân, cho phép quyết toán liền mạch cho các dịch vụ được xây dựng trên nền tảng.
Phân phối OPEN Token
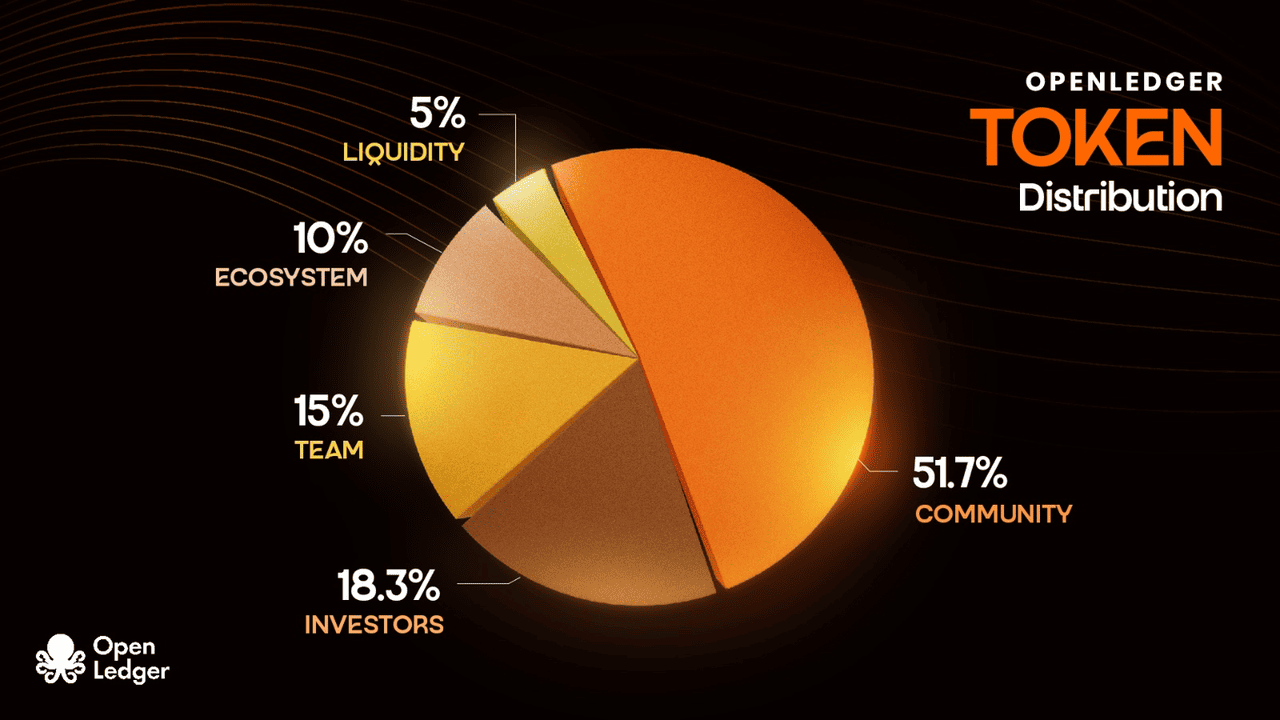
Phân bổ Token OPEN | Nguồn: Tài liệu OpenLedger
Token OPEN (mã giao dịch: OPEN) tuân thủ tiêu chuẩn ERC-20 với tổng nguồn cung tối đa là 1.000.000.000 token, và nguồn cung lưu hành ban đầu là 21,55%.
• Phân bổ cho Cộng đồng & Hệ sinh thái: 61,7%, phần lớn nhất dành cho những người đóng góp, nhà phát triển và sự phát triển của hệ sinh thái
• Nhà đầu tư: 18,3%
• Đội ngũ: 15%
• Đối tác Hệ sinh thái: 10%
• Thanh khoản: 5%
Cách giao dịch OPEN trên BingX
Cặp giao dịch OPEN/USDT trên thị trường Spot, được cung cấp bởi BingX AI insights
Cặp OPEN/USDT đã được niêm yết trên BingX, mang đến cho nhà giao dịch quyền truy cập trực tiếp vào token gốc của hệ sinh thái.
1. Tạo & xác minh tài khoản BingX: Đăng ký và hoàn thành KYC để có toàn quyền truy cập.
2. Nạp USDT: Thêm tiền qua thẻ, chuyển khoản ngân hàng hoặc chuyển crypto từ một ví khác. Chuyển tiền vào tài khoản Spot của bạn.
3. Tìm kiếm OPEN/USDT: Trên thị trường Spot, nhập “OPEN/USDT.”
4. Chọn loại lệnh:
• Lệnh thị trường → mua ngay lập tức tại mức giá hiện tại.
• Lệnh giới hạn → đặt giá của bạn và chờ thị trường đạt đến mức đó.
5. Xác nhận giao dịch: Nhập số lượng và nhấp vào Mua hoặc Bán.
6. Sử dụng Công cụ AI của BingX: Tóm tắt tin tức thị trường, thiết lập kế hoạch DCA (trung bình giá) hoặc theo dõi biến động trước khi thực hiện giao dịch.
Mẹo: Hãy theo dõi các chiến dịch niêm yết của BingX, các chiến dịch nạp tiền sớm hoặc giao dịch có thể bao gồm phần thưởng hoặc giải thưởng.
Kết luận
OpenLedger hướng đến việc mang lại sự công bằng, minh bạch và trách nhiệm giải trình cho AI bằng cách làm cho dữ liệu, mô hình và tác nhân có thể truy xuất nguồn gốc và kiếm tiền trên chuỗi. Với Proof of Attribution, những người đóng góp cuối cùng có thể được công nhận và thưởng mỗi khi công việc của họ định hình đầu ra của AI. Đối với người dùng, giao dịch OPEN/USDT trên BingX cung cấp quyền truy cập trực tiếp vào dự án, trong khi các công cụ như Datanets, ModelFactory và OpenLoRA giúp các nhà phát triển và nhà cung cấp dữ liệu dễ dàng sử dụng.
Tuy nhiên, OpenLedger vẫn là một hệ sinh thái mới nổi. Cũng như tất cả các dự án crypto, rủi ro vẫn còn, từ các lỗ hổng smart contract và biến động token cho đến sự không chắc chắn về quy định. Nếu bạn quyết định tham gia, hãy bắt đầu với số tiền nhỏ, theo dõi các kênh chính thức và chỉ đầu tư số tiền mà bạn có thể chấp nhận rủi ro.